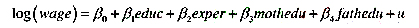题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
本题使用WAGE2.RAW中的数据。(i)估计模型并以通常的形式报告结果。保持其他因素不变,黑人和非黑
本题使用WAGE2.RAW中的数据。(i)估计模型并以通常的形式报告结果。保持其他因素不变,黑人和非黑
本题使用WAGE2.RAW中的数据。
(i)估计模型
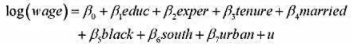
并以通常的形式报告结果。保持其他因素不变,黑人和非黑人之间的月薪差异近似为多少?这个差异是统计显著的吗?
(ii) 在这个方程中增加变量exper²和tenure², 证明即便在20%的显著性水平上, 它们也不是联合显著的。
(iii)扩展原模型,使受教育回报取决于种族,并检验受教育的回报是否的确取决于种族。
(iv)再回到原模型,但现在容许四个不同人群(已婚黑人、已婚非黑人、单身黑人和单身非黑人)的工资有差别。估计已婚黑人和已婚非黑人之间的工资差异是多少?
 答案
答案
查看答案

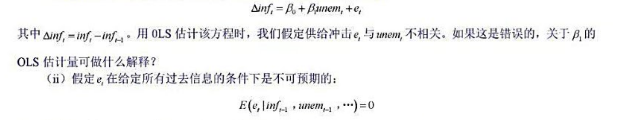

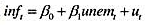 并以常用形式报告结果。
并以常用形式报告结果。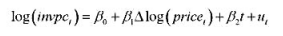
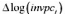 作因变量。结果与第(ii) 部分相比有何不同?时间趋势还是显著的吗?为什么是 或不是?
作因变量。结果与第(ii) 部分相比有何不同?时间趋势还是显著的吗?为什么是 或不是?
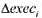 的哪个1统计量更值得信赖, 是通常的!统计量还是异方差-稳健的1统计量?为什么?
的哪个1统计量更值得信赖, 是通常的!统计量还是异方差-稳健的1统计量?为什么?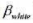 的95%的置信区间与非稳健的置信区间相比较。
的95%的置信区间与非稳健的置信区间相比较。