



 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
本题要用到HTV.RAW中的数据。 (i)考虑一个加入了父母受教育程度变量的工资方程 表述原假设:父
本题要用到HTV.RAW中的数据。
(i)考虑一个加入了父母受教育程度变量的工资方程
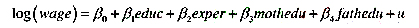
表述原假设:父亲与母亲的受教育程度对log(wage)具有相同影响。
(ii)估计第(i)部分中的模型,同时谈谈你对β,和队大小的看法。
(iii)在5%的显著性水平上,相对于双侧备择假设,通过构造一个95%的置信区间来检验第(i)部分中的原假设。你得到的结论是什么?
 答案
答案
查看答案

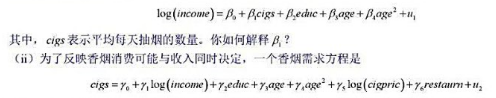

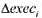 的哪个1统计量更值得信赖, 是通常的!统计量还是异方差-稳健的1统计量?为什么?
的哪个1统计量更值得信赖, 是通常的!统计量还是异方差-稳健的1统计量?为什么?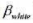 的95%的置信区间与非稳健的置信区间相比较。
的95%的置信区间与非稳健的置信区间相比较。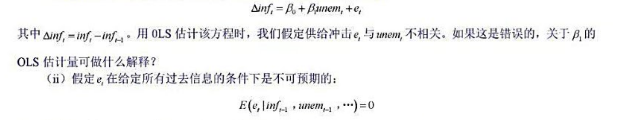


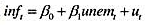 并以常用形式报告结果。
并以常用形式报告结果。


















