

 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
本题利用数据集GPA1.RAW。

请帮忙给出正确答案和分析,谢谢!
 答案
答案
查看答案
 请输入或粘贴题目内容
搜题
请输入或粘贴题目内容
搜题
 拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
请帮忙给出正确答案和分析,谢谢!
答案
 更多“本题利用数据集GPA1.RAW。”相关的问题
更多“本题利用数据集GPA1.RAW。”相关的问题
第1题
利用PHILLIPS.RAW中的数据回答本题。
(i)利用整个数据集,用OLS估计静态菲利普斯曲线方程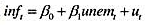 并以常用形式报告结果。
并以常用形式报告结果。
(ii)从第(i)部分中求OLS残差ut并通过ut对ut-1的回归中求出p。(在这个回归中包含一个截距项没问题。)有序列相关的强烈证据吗?
(iii)现在通过迭代普莱斯-温斯顿程序估计静态菲利普斯曲线模型。将β1的估计值与表12.2中得到的估计值相比较。添加以后的年份,估计值有很大变化吗?
(iv)不用普莱斯-温斯顿检验,而是使用迭代科克伦-奥卡特检验。p的最终估计值有多相似?β1的PW和CO估计值有多相似?
第2题
本题利用MURDER.RAW中的数据。
(i)利用1990年和1993年的数据, 用混合OLS估计方程

(iv)做第(ii)部分中的同样回归,但求异方差-稳健的t统计量。结果如何?
(v)你认为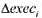 的哪个1统计量更值得信赖, 是通常的!统计量还是异方差-稳健的1统计量?为什么?
的哪个1统计量更值得信赖, 是通常的!统计量还是异方差-稳健的1统计量?为什么?
第3题
本题利用LOANAPP.RAW中的数据。
(i)估计计算机习题C7.8第(iii) 部分中的方程, 计算其异方差-稳健的标准误。将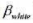 的95%的置信区间与非稳健的置信区间相比较。
的95%的置信区间与非稳健的置信区间相比较。
(ii)由第(i)部分的回归计算拟合值。其中有没有哪个估计值小于0?有没有哪个估计值大于1?而这些情况对加权最小二乘估计的应用意味着什么?
第4题
本题利用WAGEPAN.RAW中的数据。
(i)考虑非观测效应模型

(iv)现在,容许是否加入工会的差别(与受教育水平一起)在不同时期有所变化,用FD估计这个方程。1980年加入工会与不加入工会的估计工资差别是多少?1987年呢?这个差别在统计上显著吗?
(v)检验工会关系差别在不同时期没有发生变化的虚拟假设,并根据你对第(iv)部分的回答讨论你的结论。
第5题
本题利用HSE IN V.RAW中的数据。
(i)求出log(in vpc) 中的一阶自相关系数, 然后再求log(im pc) 除掉线性趋势后的自相关。对log(price) 做相同的计算。这两个序列中的哪个可能有单位根?
(ii)基于第(i)部分的结论估计方程:
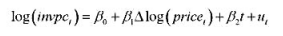
并以标准形式报告结果。对系数β1作出解释,并判断它是否统计显著。
(iii)除掉log(inypc) 的线性趋势,然后在第(ii)部分的回归方程中使用除趋势的因变量(见10.5节), R2有何变化?
(iv)现在用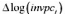 作因变量。结果与第(ii) 部分相比有何不同?时间趋势还是显著的吗?为什么是 或不是?
作因变量。结果与第(ii) 部分相比有何不同?时间趋势还是显著的吗?为什么是 或不是?
第6题
利用NYSE.RAW中的数据回答本题。
(i) 估计方程(12.47) 中的模型并求OLS残差平方。求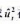 在整个样木中的平均值、最小值和最大值。
在整个样木中的平均值、最小值和最大值。
(ii) 利用OLS残差平方估计如下的异方差模型
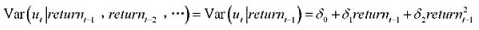
报告估计系数、标准误、R²和调整R²。
(iii) 将条件方差描述成滞后return-1的函数。方差在return-1取何值时最小?方差是多少?
(iii)为了预测动态方差,第(ii)部分的模型得到了负的方差估计值吗?
(v)第(ii)部分中的模型拟合效果比例12.9中的ARCH(1)模型更好还是更差?请解释。
(vi)在方程(12.51)的ARCH(1)回归中添加二阶滞后。这个滞后看起来重要吗?这个ARCH(2)模型比第(ii)部分中的模型拟合得更好吗?
第7题
本题利用TRAFFIC 2.RAW中的数据。前面的计算机习题C 10.11曾要求你分析这些数据。
(i)计算变量prc fat的一阶自相关系数。你认为prc fat包含单位根吗?失业率也一样吗?
(ii)估计一个将prc fal的一阶差分Aprcfat与计算机习题C10.11第(vi) 部分中同样变量相联系的多元回归模型,只是你还应该对失业率进行一阶差分。于是,模型中包含一个线性时间趋势、月度虚拟变量、周末变量和两个政策变量:不要将这些变量进行差分。你发现了什么有意思的结论吗?
(iii)评论如下命题:“在进行多元回归之前,我们总应该将怀疑具有单位根的时间序列进行一阶差分,因为这样做是一种安全策略,而且应该得到与使用水平值类似的结论。”[在回答这个问题时,最好先做(如果你还没有做过的话)计算机习题C10.11第(vi)部分中的回归。]
第8题
本题使用HTV.RAW中的数据。
(i)基于整个样木, 利用解释变量educ、abil、exper、nc、west、south和urban, 利用OLS估计log(wage)的一个模型。报告教育的估计回报及其标准误。
(ii)现在, 仅利用educ<16的人群来估计第(i) 部分中的方程。样本损失了多大的比例?现在, 多读一年书的估计回报是多少?它与第(i)部分中的结果相比如何?
(iii)现在, 去掉所有wage≥20的观测, 于是, 样本中剩下每个人每小时工资都不足20美元。做第(i) 部分中的回归, 并评论educ的系数。(由于正常的断尾回归模型都假定y是连续的, 所以理论上我们去掉wage≥20还是去掉wage>20都无所谓。但在这个应用研究中, 由于有些人正好每个小时挣20美元, 所以二者略有差异。)
(iv)利用第(ii) 部分中的样本, 应用断尾回归[上断点为log(20) ] .假定第(i) 部分中得到的估计值是一致的,这个断尾回归能够重新得到整个总体中的教育回报估计值吗?
第9题
利用数据集401KSUBS.RAW。
(i)利用OLS估计e401k的一个线性概率模型,解释变量为inc,inc²,age,age²和male。求通常的OLS标准误和异方差-稳健的标准误。它们有重要差别吗?
(iii)对第(i)部分估计的模型求怀特检验,并分析系数估计值是否大致对应于第(ii)部分中描述的理论值。
(iv)在验证了第(i)部分的拟合值都介于0和1之间后,求这个线性概率模型的加权最小二乘估计值。它们与OLS估计值有重大差别吗?
第10题
(i)在数据集JTRAIN2.RAW中,男人参加工作培训的比例是多大?在JTRAIN3.RAW中的比例又是多大?你认为为什么存在这么大的差距?
(ii)利用JTRAIN2.RAW,做re78对train的简单回归。参与工作培训对真实工资的估计影响有多大?
(ii)现在,在第(ii)部分的回归中增加控制变量re74,re75,educ,age,black和hisp。工作培训对re78的估计影响变化大吗?何以至此?(提示:记得这些都是实验数据。)
(iv)利用JTRAIN3.RAW中的数据做第(ii)部分和第(iii)部分的回归,只报告train的估计系数及其:统计量。现在,控制额外因素的影响如何?为什么?
(v)定义avgre=(re74+re75)/2。求这两个数据集中的样本均值、标准差、最小值和最大值。这些数据集代表了1978年同样的总体吗?
(vi)在数据集JTRAIN2.RAW中,几乎96%的男性的avgre低于10000美元。只利用这些男性的数据,做re78对train,re74,re75,educ,age,black和hisp的回归,并报告培训估计值及其:统计量。对JTRAIN3.RAW
也只利用avgre ≤10的男性做同样的回归。就这个低收入男性子样本而言,实验数据集和非实验数据集估计的培训效应有何差别?
(vii)现在,只针对1974年和1975年失业的男性,利用每个数据集做re78对train的简单回归。培训的估计值又有何差别?
(viii)利用你前面的回归结果,试讨论在比较实验估计值和非实验估计值的背后,拥有可比较总体的潜在重要性。



















