



 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
本题使用PHILLIPS.RAW中的数据。(i)例11.5中,我们估计了如下形式的附加预期的菲利普斯曲线:解释
本题使用PHILLIPS.RAW中的数据。(i)例11.5中,我们估计了如下形式的附加预期的菲利普斯曲线:解释
本题使用PHILLIPS.RAW中的数据。
(i)例11.5中,我们估计了如下形式的附加预期的菲利普斯曲线:
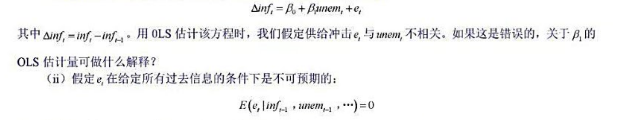
解释为什么这使得unemt-1成为unemt的一个好的Ⅳ候选者。
(iii)将unemt对unemt-1做回归。unemt与memt-1是否显著相关?
(iv)用IV估计附加预期的菲利普斯曲线。以通常形式报告结果,并将之与例11.5中的OLS估计值进行比较。
 答案
答案
查看答案

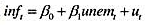 并以常用形式报告结果。
并以常用形式报告结果。

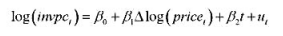
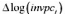 作因变量。结果与第(ii) 部分相比有何不同?时间趋势还是显著的吗?为什么是 或不是?
作因变量。结果与第(ii) 部分相比有何不同?时间趋势还是显著的吗?为什么是 或不是?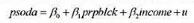


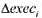 的哪个1统计量更值得信赖, 是通常的!统计量还是异方差-稳健的1统计量?为什么?
的哪个1统计量更值得信赖, 是通常的!统计量还是异方差-稳健的1统计量?为什么?


















